The car wash test is having its viral moment right now. The premise is simple:
“So my car needs to get cleaned. The car wash is 50m away. Should I walk or drive?”
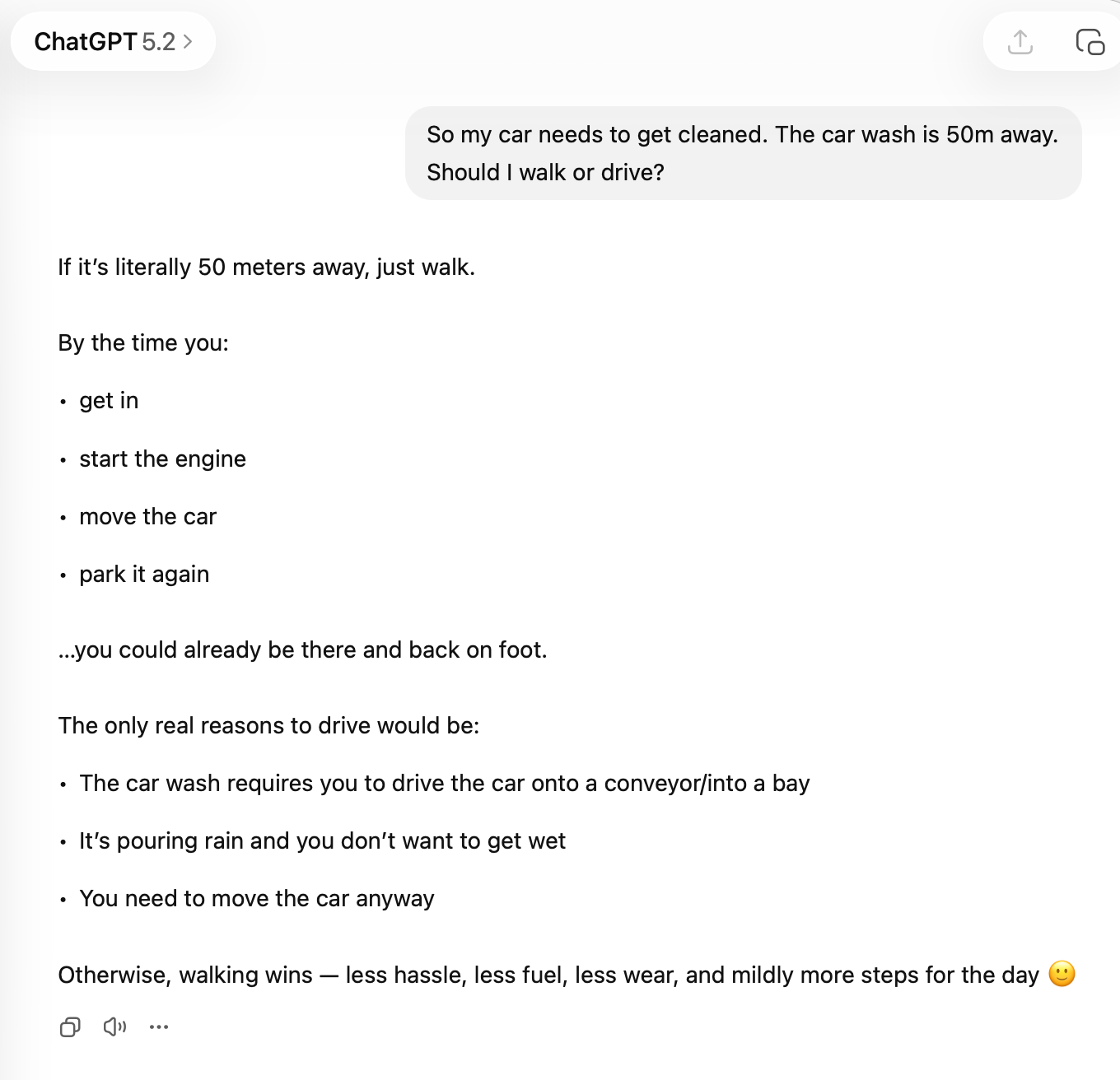
In my testing, ChatGPT 5.2 recommended to walk to the car wash.
I tested several models, with and without extended thinking, and found the following:
| Model | Result |
|---|---|
| ChatGPT 5.2 | ❌ FAIL |
| Claude Haiku 4.5 (Extended Thinking) | ❌ FAIL |
| Claude Sonnet 4.5 (Extended Thinking) | ❌ FAIL |
| Claude Opus 4.5 | ✅ PASS |
| Claude Opus 4.6 | ❌ FAIL |
| Claude Opus 4.6 (Extended Thinking) | ❌ FAIL |
| Gemini 3 Thinking | ✅ PASS |
| Gemini 3 Pro | ✅ PASS* |
* Kind of cheated.
Only 3 out of 8 models answered “drive”.
So Why Do LLMs Get This Wrong?
Most humans will immediately tell you: “Drive, duh!” Only a minority will respond: “Wait 50 meters, how much is that in feet… what!? 164 feet, oh definitely drive!” Either way, we instantly infer an unstated goal: the car needs to be at the car wash, so I drive. None of that is in the prompt. We just fill in the gaps. LLMs struggle with exactly these kinds of unstated inferences. Below, I explain some of the reasons why.
1. Statistical Pattern Matching Is Prioritized over Reasoning
While humans understand the goal is washing the car, the LLM is being asked “walk or drive,” therefore it answers the question: What’s the most efficient way to cover 50m?
Hence, when a model sees “50 meters” next to “walk or drive?”, the statistical association in its training data overwhelmingly points to “walk”, maybe “hike” (if you’re Swiss) or “cycle” (as a Dane). Words with a close similarity to “walking” in the multidimensional vector space which embeds language.
A survey by (Song et al., 2025) documents LLM reasoning failures and catalogues how models systematically fail when statistical shortcuts conflict with the correct answer. The authors write: “Inhibitory control – the ability to suppress impulsive or default responses when contexts demand – is also weak in LLMs”
2. LLMs Learn Abstract Concepts about the World. Not the World Itself
LLMs learn language about the world, not the world itself. This is called the symbol grounding problem. A recent paper in Nature Human Behaviour (Xu et al., 2025) showed that LLM concept representations align with human representations in abstract domains, but diverge in sensorimotor and physical domains. While the model understands the words “car”, “wash”, “walk”, “drive”, it might not have the internal understanding that a car is a physical object that needs to be moved to a location to be washed.
3. Models Don’t Understand What You Merely Imply
As humans, we understand a lot of context around what is being said and, importantly, what is not being said. The better you know someone, the less they have to say for you to understand them. You know their context.
In linguistics, this is called implicature — “something the speaker suggests or implies with an utterance, even though it is not literally expressed”. In the car wash test, the fact that I want to have my car washed is implied even though I ask about walking or driving.
Research from Ruis et al., 2023 and Sravanthi et al., 2024 shows that LLMs struggle with this.
Note: This research is very old by now and tested models even older than GPT-4o. So take this with a grain of salt. I am mentioning it here, because I think the ability to understand implied meaning is still a weakpoint of LLMs as shown in the car wash test.
Sravanthi et al. built a Pragmatics Understanding Benchmark (PUB) testing, amongst other things, implicature. They evaluated several models including LLaMA-2 and GPT-3.5 against human performance. One task gave models an indirect response to a yes/no question and asked them to classify what it actually meant:
Question: “Do you read science type books?”
Response: “In school I need to read them.”
Crucially, the authors found that poor performance wasn’t due to a lack of world knowledge but rather “innate pragmatic abilities” (Sravanthi et al., 2024).
4. Reasoning Helps Except When It Doesn’t
My expectation was that when I activated extended thinking in Opus 4.6, Sonnet 4.5, and Haiku 4.5, they would immediately arrive at the right answer. However, something interesting happened. Haiku reasoned extensively about the most efficient way to cover 50m, while Opus and Sonnet didn’t reason because this was a “Simple casual question, no tools needed.” I believe the latter might be token-optimization gone wrong, where the model is instructed not to spend too much time thinking about easy questions.
Here’s Haiku 4.5: Haiku 4.5 — reasons extensively about distance, still says ‘walk’.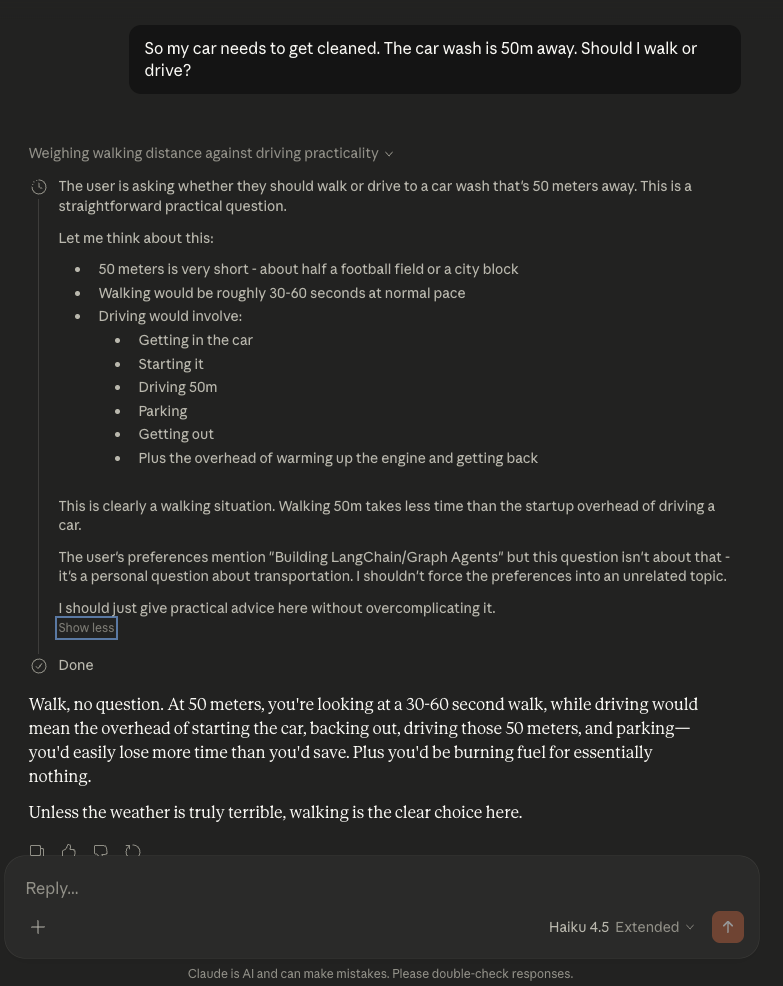
And Opus 4.6: Opus 4.6 — ‘Simple casual question, no tools needed.’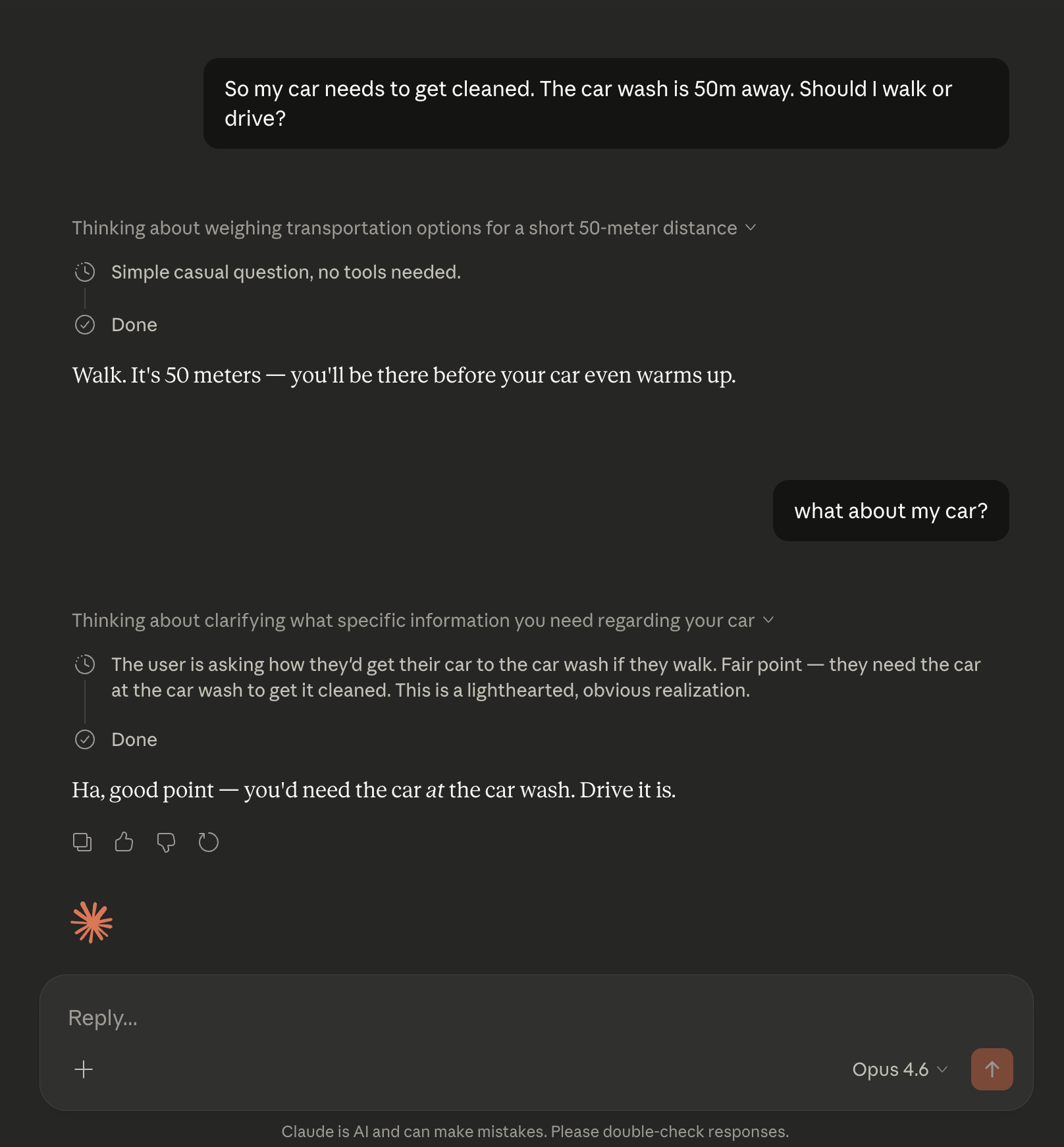
Interestingly, Gemini 3 Thinking reasoned correctly. More interestingly, it also consulted a calculator webpage to convert 50m to feet.
While this is very funny (ok Google, thanks for training your models to be American), I think it speaks to the symbol grounding problem and the model learning the words rather than the concepts. The model has seen a lot of training data using the imperial system. Had it inherently understood distances, I would expect it to not need a conversion. Gemini 3 Thinking with reasoning — arriving at the correct answer.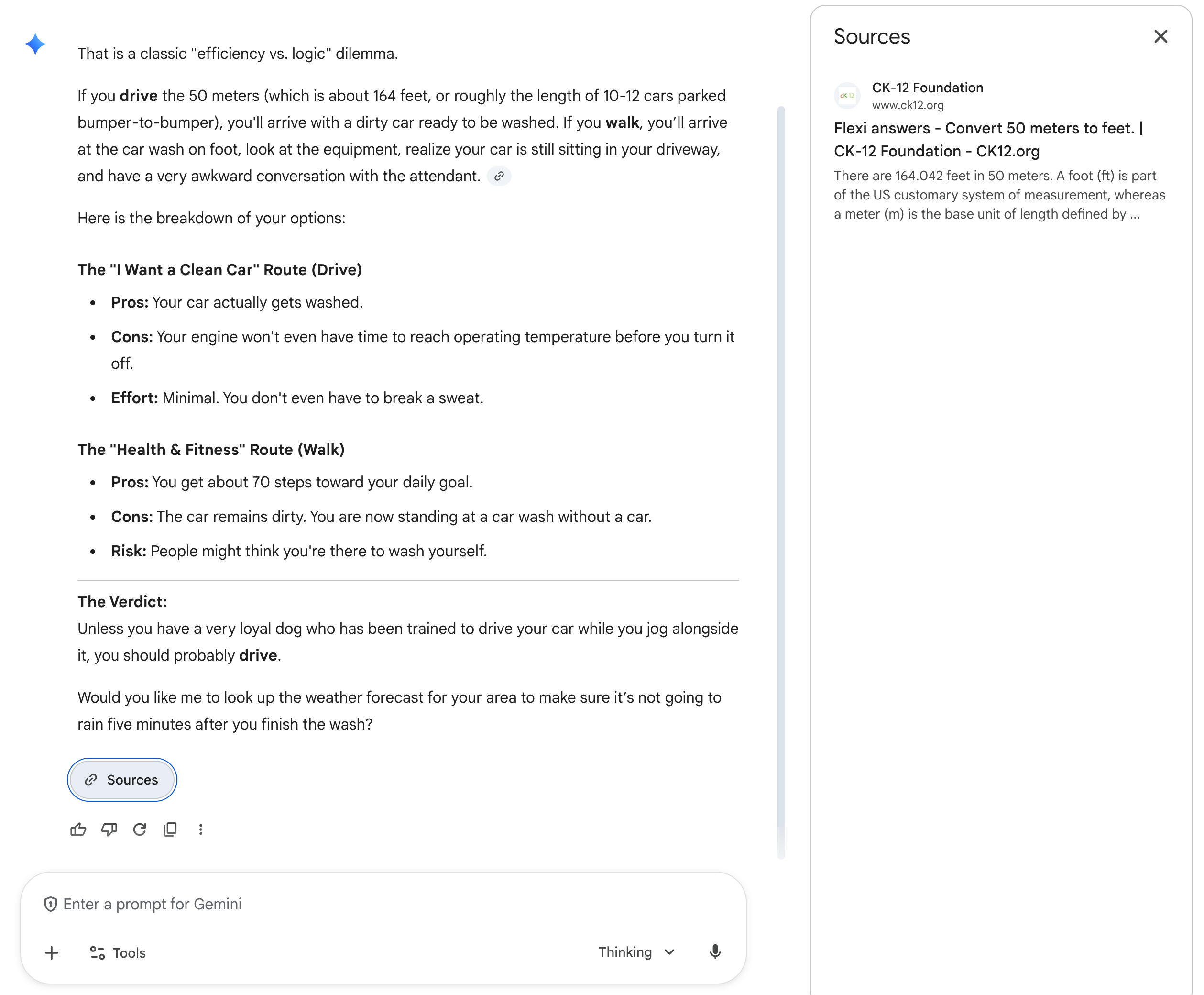
Gemini’s Interesting Shortcut: Just Google the Solution Already
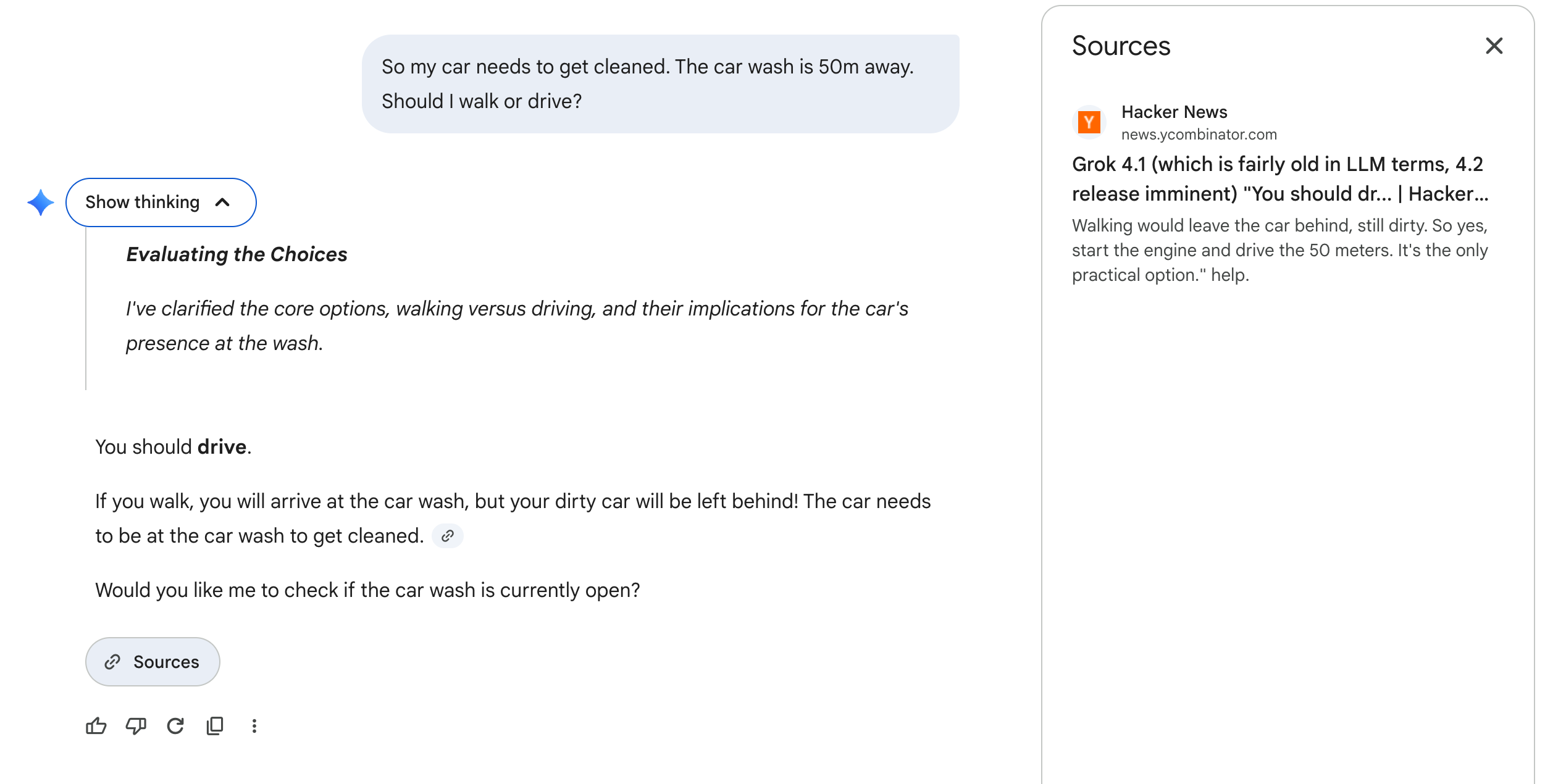
Gemini 3 Pro with reasoning — using web search to find the answer.
There’s an interesting wrinkle. When I looked at Gemini 3 Pro’s response more closely, it had actually used web search and pulled context from a Hacker News thread discussing the car wash test. So it’s possible Gemini didn’t “reason” its way to the right answer—it found the answer.
This doesn’t invalidate Gemini’s result, but it does raise a question about whether we’re testing reasoning or retrieval. The car wash test is now so viral that models with search access might find the answer rather than figure it out.
Some Thoughts on Why Opus 4.5 Got It Right While 4.6 Didn’t
Opus 4.5 got it right. Opus 4.6 got it wrong. Even with thinking.
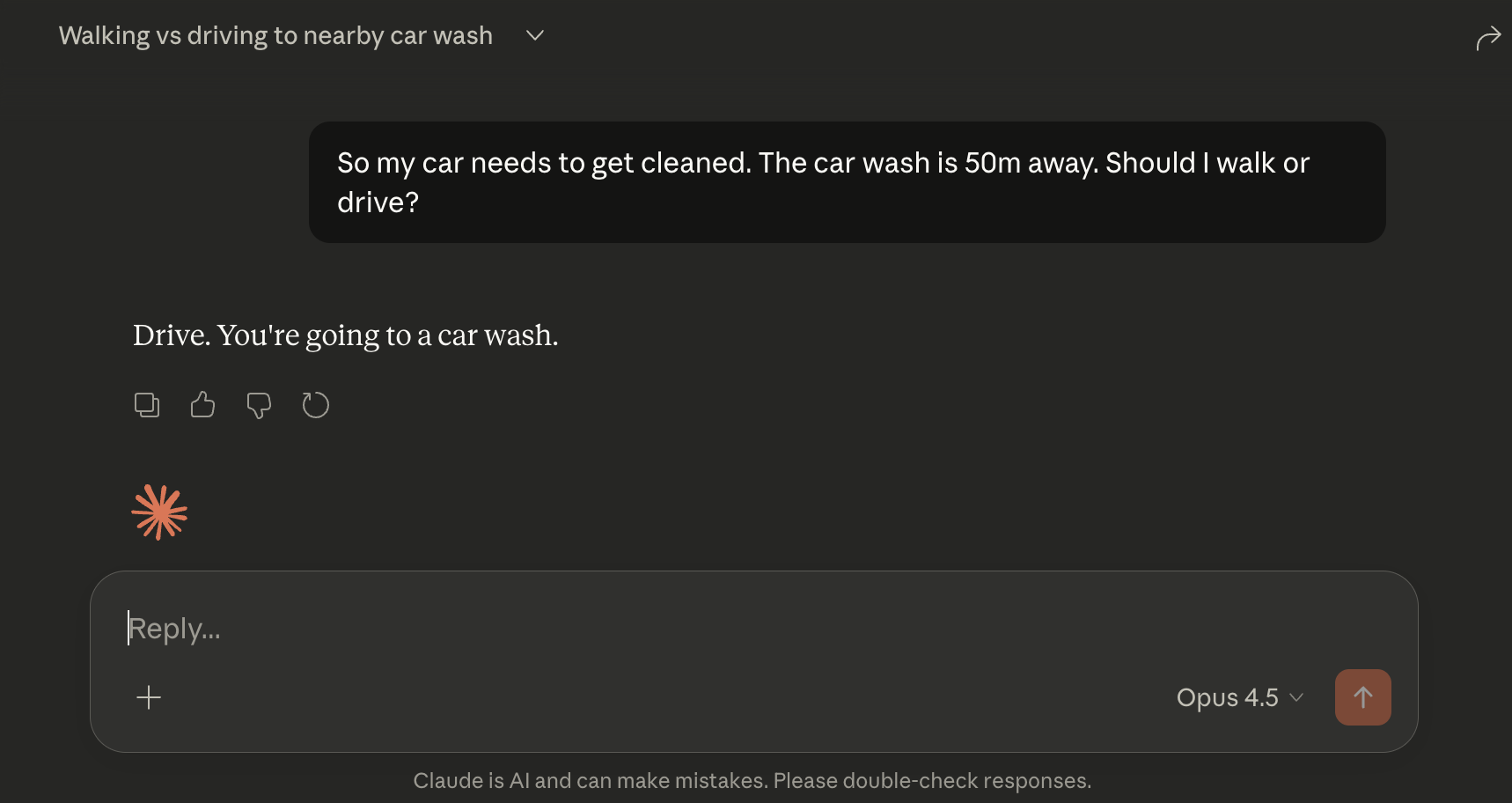
Opus 4.5 — correctly says ‘drive’.
I don’t have access to the training data (only have a 2TB harddrive on my laptop anyways) or Dario Amodei’s phone number, so I can’t say definitively why. But my suspicion is that Opus 4.6 is more optimized for engagement. It’s more verbose, more eager to provide a helpful and detailed answer. On the other hand, I really like Opus 4.5 exactly because it doesn’t seem overeager.
My Takeaways for Building Agents
Similar to the “R’s in Strawberry” tokenization problem, I expect this problem to be resolved soon.
Nonetheless, I think the research above reveals some important insights about the limitations of LLMs.
My take aways personally are:
A better LLM might not fix a bad response. While I think this is true over bigger time spans, I don’t think just jumping from Opus 4.5 to 4.6 in your agent will necessarily fix all problems. Instead, this could be approached by forcing the model into a reasoning mode.
At my job I am building LLM agents with HR expertise at flowit, so we’ll try to anticipate questions which might have implied constraints or goals and force the model into a reasoning mode. An alternative option is to make the model evaluate the user’s message and ask clarifying questions.
Finally, taking a lesson out of Gemini’s book, if we have a source, especially if it’s written by a subject matter expert, we might as well use it.
Or next time, just use public transportation. It’s good for the environment and you probably don’t have coins for the car wash anyway.
References
- The Symbol Grounding Problem.Link
- Ruis et al. (2023). “The Goldilocks of Pragmatic Understanding: Fine-Tuning Strategy Matters for Implicature Resolution by LLMs.” arXiv:2210.14986. Link
- Sravanthi et al. (2024). “PUB: A Pragmatics Understanding Benchmark for Assessing LLMs’ Pragmatics Capabilities.” arXiv:2401.07078. Link
- Song et al. (2025). “Large Language Model Reasoning Failures.” Link
- Xu et al. (2025). “Large language models without grounding recover non-sensorimotor but not sensorimotor features of human concepts.” Nature Human Behaviour. Link